

GLM-4.5V 是什么?
GLM-4.5V 是智谱基于 GLM-4.5-Air 文本基座构建的开源视觉-语言模型(总参数约 106B,激活参数约 12B),面向图像、视频、文档与 GUI 屏幕等全场景的多模态推理与理解。模型在多项公开视觉多模态基准上达到同级别开源模型的领先效果,并提供“思考模式”开关以在响应速度与推理深度之间灵活权衡;同时兼顾工程化落地,支持在线体验、API 调用与本地化部署。

GLM-4.5V 的主要功能
- 多模态推理:统一处理图像、视频、文档、屏幕内容,支持跨图/跨帧/跨页的综合理解。
- 视觉定位(Grounding):按指令精准框选并返回坐标,适配质检、遥感、检索等业务。
- 视频理解:长视频分镜与事件识别,结合三维特征建模提升时序分析效果。
- 复杂图表与长文档解析:图文同读,提升表格/图表/版式信息的保留与抽取精度。
- GUI Agent 能力:读屏识别控件与层级关系,推断可执行操作,支撑桌面/网页自动化。
- 可控推理(思考模式):一键在“快速响应/深度推理”间切换,满足不同延迟与准确度需求。
- 训练与架构要点:视觉编码器 + MLP 适配器 + 语言解码器;引入 3D-RoPE、双三次插值与三阶段训练(预训练→SFT〔含显式链式思维〕→RL〔RLVR/RLHF〕)。
GLM-4.5V 的适用场景或人群
- 开发者 / 工程师:将 VLM 推理、定位与读屏能力集成到应用或 Agent/RPA 系统。
- 企业数据与运营团队:研报/合同等长文档解读、图表抽取、视频要点分析与内容审核。
- 研究者:以开源权重为基线开展多模态推理、评测与可解释性研究。
- 前端 / 设计 / 测试:基于截图或交互视频进行“前端复刻”,还原页面结构与交互逻辑。
- 安防 / 巡检 / 遥感:目标检测、质检与监测分析等需要精确定位与推理的场景。
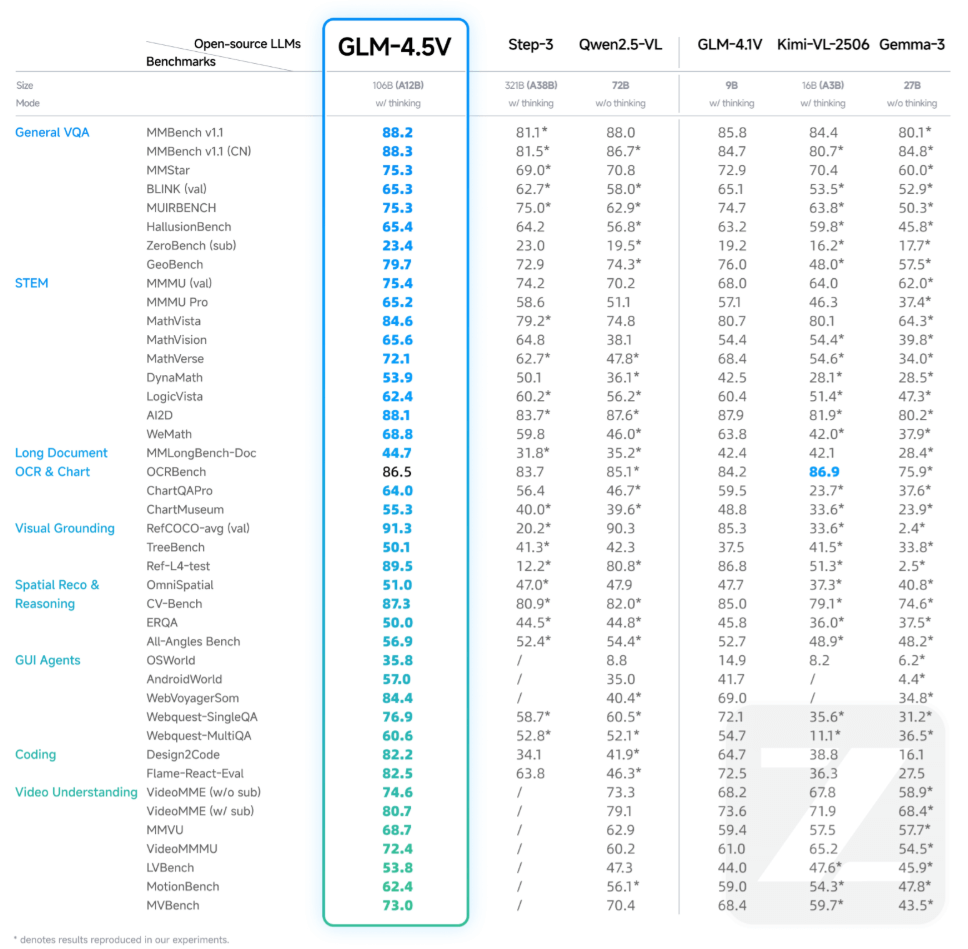
GLM-4.5V 的性能表现
GLM-4.5V 在 42 个公开视觉多模态榜单中综合效果达到同级别开源模型 SOTA 性能,涵盖图像、视频、文档理解以及 GUI Agent 等常见任务。
如何使用 GLM-4.5V
- 在线体验:前往 z.ai 选择 GLM-4.5V 上传图片/视频,或使用智谱清言(APP/网页)开启“推理模式”。
- 开源获取 / 本地部署:在 GitHub、Hugging Face、魔搭社区下载模型与示例;提供开源桌面助手(截屏/录屏 + 多模态推理)便于快速体验。
- 推理与微调:兼容主流推理后端(如
transformers、vLLM、SGLang);LLaMA-Factory 提供多图示例与标签格式,便于 SFT/指令对齐。 - API服务:通过 BigModel.cn 接入,官方提供示例、参数与价格信息(并有限时赠送 token 资源包的活动)。
GLM-4.5V 的官方资源
- 官网 / 在线体验:z.ai
- GitHub 仓库:https://github.com/zai-org/GLM-V
- Hugging Face(模型合集):https://huggingface.co/collections/zai-org/glm-45v-68999032ddf8ecf7dcdbc102
- 魔搭社区(模型合集):https://modelscope.cn/collections/GLM-45V-8b471c8f97154e
- API 与文档:http://docs.bigmodel.cn/api-reference
- 桌面助手 Demo(HF Spaces):https://huggingface.co/spaces/zai-org/GLM-4.5V-Demo-App
©版权声明:如无特殊说明,本站所有内容均为AIHub.cn原创发布和所有。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。否则,我站将依法保留追究相关法律责任的权利。