

Step-Audio-2-mini 是什么?
Step-Audio 2 mini 是阶跃星辰发布的开源端到端语音大模型,采用统一架构实现语音理解、推理与生成,支持语音识别、跨语种翻译、情感解析与自然对话。在多个国际基准测试中取得 SOTA 成绩,并率先具备语音原生 Tool Calling 能力,综合性能超越同类开源模型和 GPT-4o Audio,现已在 GitHub、Hugging Face 和 ModelScope 开源。
Step-Audio-2-mini 的主要特性
- 先进的语音和音频理解:通过理解并推理语义信息、副语言信息和非语音信息,在自动语音识别(ASR)和音频理解方面表现出色。
- 智能语音对话:实现自然且智能的交互,适用于各种对话场景和副语言信息。
- 工具调用和多模态检索增强生成(RAG):通过利用工具调用和 RAG 访问现实世界知识(包括文本和声学),Step-Audio 2 可以在多种场景下生成较少幻觉的响应,并且还能够根据检索到的语音切换音色。
- 最先进性能:在各种音频理解和对话基准测试中,与其它开源和商业解决方案相比,Step-Audio 2 达到了最先进的性能。
- 开源:Step-Audio 2 mini 和 Step-Audio 2 mini Base 在 Apache 2.0 许可下发布。
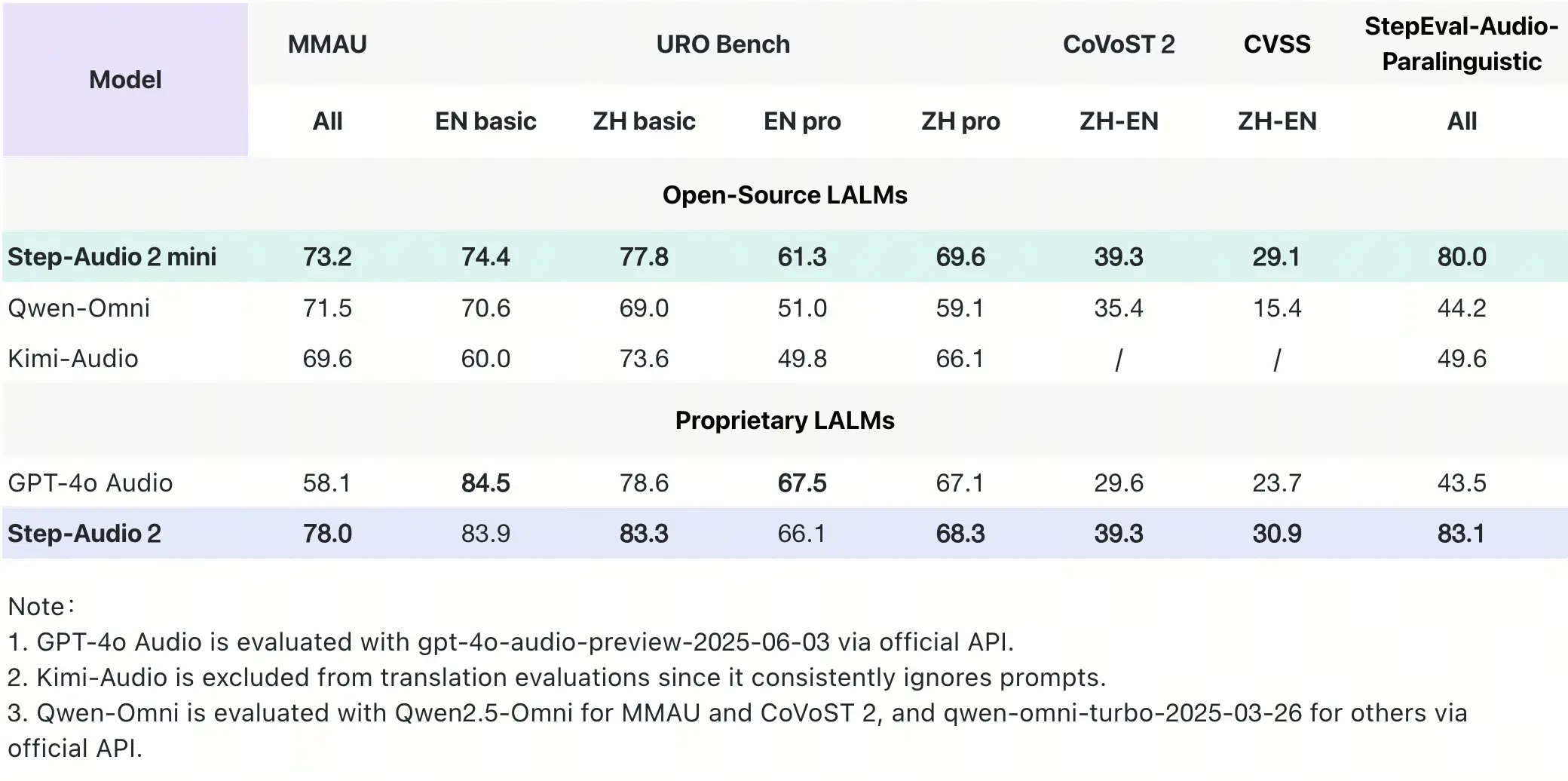
Step-Audio-2-mini 的模型评测
Step-Audio 2 mini 在多个关键基准测试中取得 SOTA 成绩,在音频理解、语音识别、翻译和对话场景中表现突出,综合性能超越 Qwen-Omni 、Kimi-Audio 在内的所有开源端到端语音模型,并在大部分任务上超越 GPT-4o Audio。
Step-Audio-2-mini 的相关资源
Step-Audio 2 mini 模型现已上线 GitHub、Hugging Face 等平台,也已上线阶跃星辰开放平台。
- 体验地址:https://realtime-console.stepfun.com
- GitHub:https://github.com/stepfun-ai/Step-Audio2
- 模型地址:
- 技术报告:https://arxiv.org/abs/2507.16632
©版权声明:如无特殊说明,本站所有内容均为AIHub.cn原创发布和所有。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。否则,我站将依法保留追究相关法律责任的权利。
