当前位置:
首页>AI资讯>微信里识别LOGO又快又准?背后有OCR模块一份功劳
LOGO作为公司或品牌的代表性标志,具有较强的识别和推广作用。本文将介绍微信扫一扫及长按识图中LOGO检测及识别的相关技术。
扫一扫识物和长按识图上线以来,可识别的类目已经从商品扩充到了包含植物、动物、地标、菜品、汽车、名画等的各个垂类。随着用户量的上升,对于LOGO检测和识别的需求愈发强烈,LOGO作为品牌的标识,可以让用户快速认识和了解品牌,同时也能更快地接入商家的服务,进入到商家的公众号及小程序。
针对LOGO识别,最直接的解决思路就是检测到query图中的logo区域进行分类,或者采用检索的方式从gallery里面找到距离最近的图片,同时需要限制这个距离剔除库中不存在此LOGO的情况。但在实现过程中,我们发现LOGO识别主要存在以下难点:
1、LOGO款式多,同一商家可能具有不同款LOGO,且不同款间类间差异小;
2、LOGO既有纯文本的样式,又有纯图案的样式,还有艺术字样式;
3、LOGO更新迭代快,商家可能不定时更换LOGO,要求模型的变通性强。
针对以上难点,我们在设计LOGO识别方案时,为了更加灵活的迭代算法,采用了检索的方式。同时,由于视觉检索模型对于文本的特征表达能力不足,为了兼顾了文本和图案类型的LOGO,我们还引入了OCR模块来进行二次验证,最终得到了如下图所示的整体解决方案。
如上图所示,首先进行LOGO检测获取目标区域,再对目标进行检索找到top1检索距离小于一定阈值的结果作为预识别结果,根据预识别结果判断是否为文本,如果为文本则进行OCR识别后做二次验证,计算文本相似度,满足一定阈值条件才输出结果,如果不是文本则在直接输出结果。
在进行LOGO识别前,首先需要解决的问题是在图像中检测到LOGO,我们起初尝试复用多源异构数据的检测器进行LOGO分支的开发,但实现中发现LOGO数据会与历史遗留的大部分商品数据的存在重叠,异构模式下两个冲突的分支对主干backbone会产生影响,由于LOGO广泛存在于商品中,且大部分LOGO为较小的目标。
为了更好地检测LOGO且不对主干商品和垂类检测产生影响,我们构造了一个独立于商品检测器的双流retinanet LOGO检测器。我们将数据分为两类,一类是具有表观一致性的LOGO数据,另一类是无表观一致性的数据利用全图框来表征(如大量的背景图及噪声类),两组数据独立交替更新参数共享的检测网络。最后引入全图分类模块和梯度裁剪策略,加快模型收敛防止梯度爆炸。部署阶段我们采用TensorRT int8量化模型来进行优化提速。
此外,为了解决长按识图场景下对于部分商家图片的LOGO大多是拼接在图片角落的方式,或者以水印方式贴上的LOGO,我们引入了一个在线LOGO拼接的数据增强方式。对于标注好的真实样本,将LOGO的patch作为增强样本,随机padding到原图无LOGO处。在合成过程中,我们主要采用了以下两种方式来随机合成:
mixup是对图像进行混类增强的算法,可以将不同类之间的图像进行混合,从而扩充训练数据集。
mixed_imgx=λ∗imgx+(1−λ)∗logo_patch
直接对目标区域位置进行图像替换,类似构建水印的方式直接合成。
具体实现中也会采用两种方式来选取合成区域,一种是将图像划分为特定子区域,在无LOGO区域内采用上述方式合成,另一种是采用特定角落区域合成LOGO。
在LOGO识别环节,我们观察到LOGO具有样式多且款式多的情况。LOGO的类间差异大,LOGO的形式可能有图案等视觉表征能力强的类别,也有文本类等视觉表征能力差的类别,以及介于两者之间的艺术字类目。另一方面,同一款商家可能具有多款LOGO,包括LOGO升级迭代带来的多款LOGO,以及同时包含文本类和图案类的LOGO的情况。
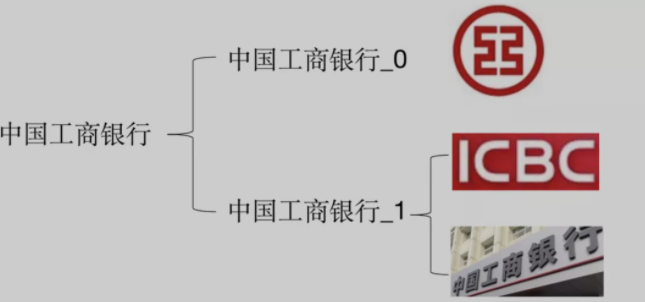
为了实现文本类LOGO与图案类LOGO(包含艺术字)的区别,以中国工商银行为例我们构建了新的LOGO体系如下图所示。其中由于纯CNN模型对于文本图像的视觉特征表达能力不足,因此我们引入了OCR模型来对文本类的样本进行进一步地检验。
识别模型训练过程中,我们将同一个商家的不同款式LOGO作为不同的类别来进行细粒度分类模型的训练,沿用其他垂类基于互学习训练的网络(如下图所示)来作为特征提取backbone,基于resnet152和inceptionv4的互学习结构训练分类模型,去掉fc后通过网络提取特征,最终构建faiss库进行LOGO检索。
在LOGO体系分类中对于文本类的样本,视觉特征表达能力有所欠缺,对于部分相似的文本容易出现误召回,为此我们设计了OCR二次验证模块。我们会对query区域进行文字识别,然后计算query与召回结果的文本相似度,选取一定阈值作为输出条件。关于OCR相关算法介绍可参考微信OCR图片文字提取。
本文介绍了微信扫一扫中LOGO检测及识别的相关算法。LOGO识别上线后丰富了扫一扫及识图的场景,同时也能推送相关的商家官方区或者公众号,更便于用户寻求相关服务。
后续对于LOGO识别的探索还可以从更多方向进行。一方面可以在LOGO检测端引入OCR文本检测的相关算法,如引入dbnet[5]的分割监督,从而端到端得到LOGO的文本概率值,另一方面可以在识别过程中的特征表达中直接计算预测文本与top1的文本相似度。
©版权声明:如无特殊说明,本站所有内容均为
AIHub.cn原创发布和所有。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。否则,我站将依法保留追究相关法律责任的权利。