

2015年9月8日,阿里旗下通义千问团队正式发布最新语音识别模型 Qwen3-ASR-Flash。该模型基于 Qwen3 底座训练,结合千万小时级别的多模态与 ASR 数据,主打高精度与高鲁棒性,支持 11 种语言及多种方言,并在中英文及多语种基准测试中取得领先成绩。
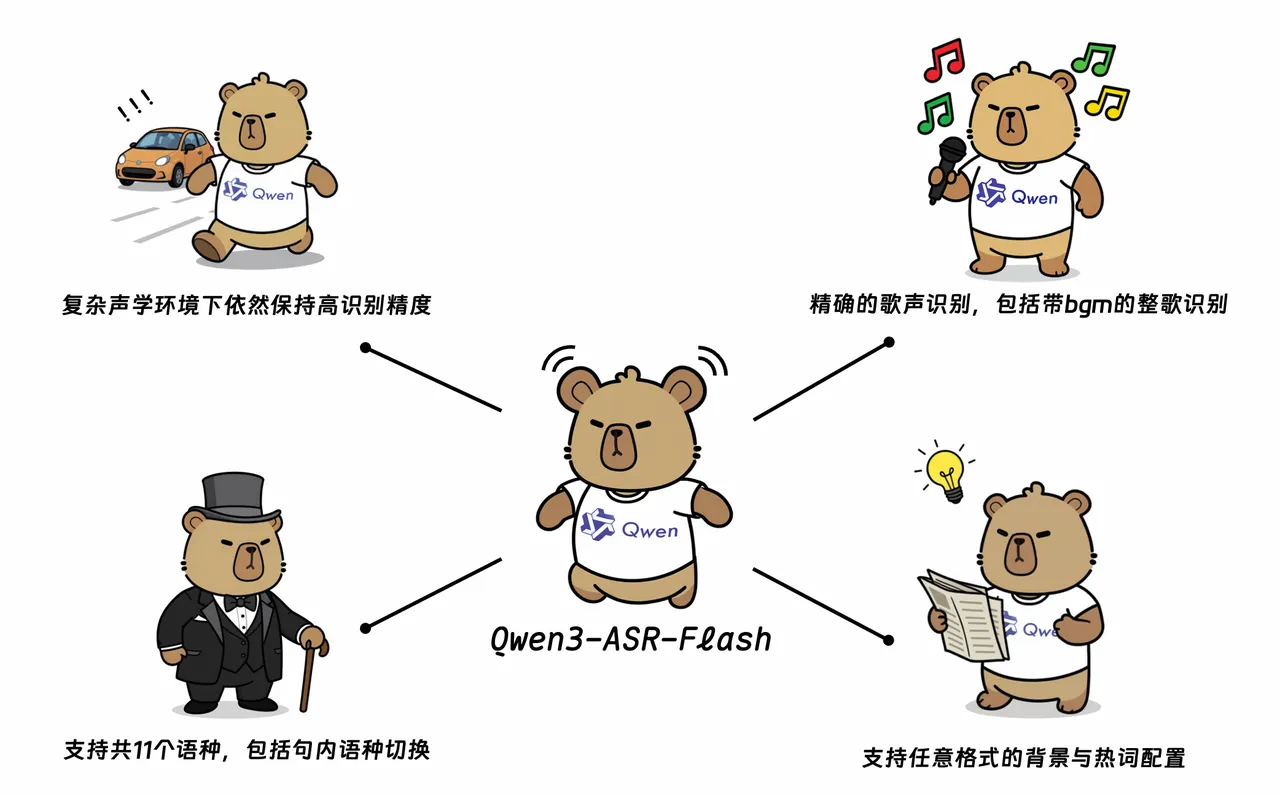
Qwen3-ASR-Flash 最大亮点在于 支持上下文定制与歌声识别。用户可输入关键词、段落或整篇文档作为背景提示,模型将智能匹配命名实体与术语,实现更精准的定制化转写。同时,它还能识别清唱或伴奏下的完整歌曲,实测错误率低于 8%。
在功能层面,Qwen3-ASR-Flash 具备 语种识别、非人声拒识与噪声环境下的稳定转写,适配教育课堂、媒体采访、车载语音、在线客服等多种场景。官方已在 ModelScope、HuggingFace 平台开放在线体验,并通过 阿里云百炼 API 提供接口调用。
业内人士认为,该模型的推出不仅强化了通义千问在语音领域的技术布局,也为多语种、多场景下的语音转文字服务带来新的可能。
体验入口:
- ModelScope:https://modelscope.cn/studios/Qwen/Qwen3-ASR-Demo
- HuggingFace:https://huggingface.co/spaces/Qwen/Qwen3-ASR-Demo
- 阿里云百炼 API:https://bailian.console.aliyun.com/?tab=doc#/doc/?type=model&url=2979031
©版权声明:如无特殊说明,本站所有内容均为AIHub.cn原创发布和所有。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。否则,我站将依法保留追究相关法律责任的权利。