

2025年7月4日,阿里通义实验室正式发布了旗下首个音频生成模型——ThinkSound。这一突破性技术首次将思维链(CoT)概念应用于音频生成领域,让AI可以像“专业音效师”一样理解画面事件与声音的关系,突破了传统音频生成的局限。
ThinkSound的核心亮点在于其精确的空间音频生成能力,不仅能够为视频画面配音,更能根据画面内容做出深入的推理,生成高保真、时序精确的音效。这一技术的发布,将大大推动影视、游戏等创意行业的发展,提升音效与画面之间的语义连贯性和动态表现。
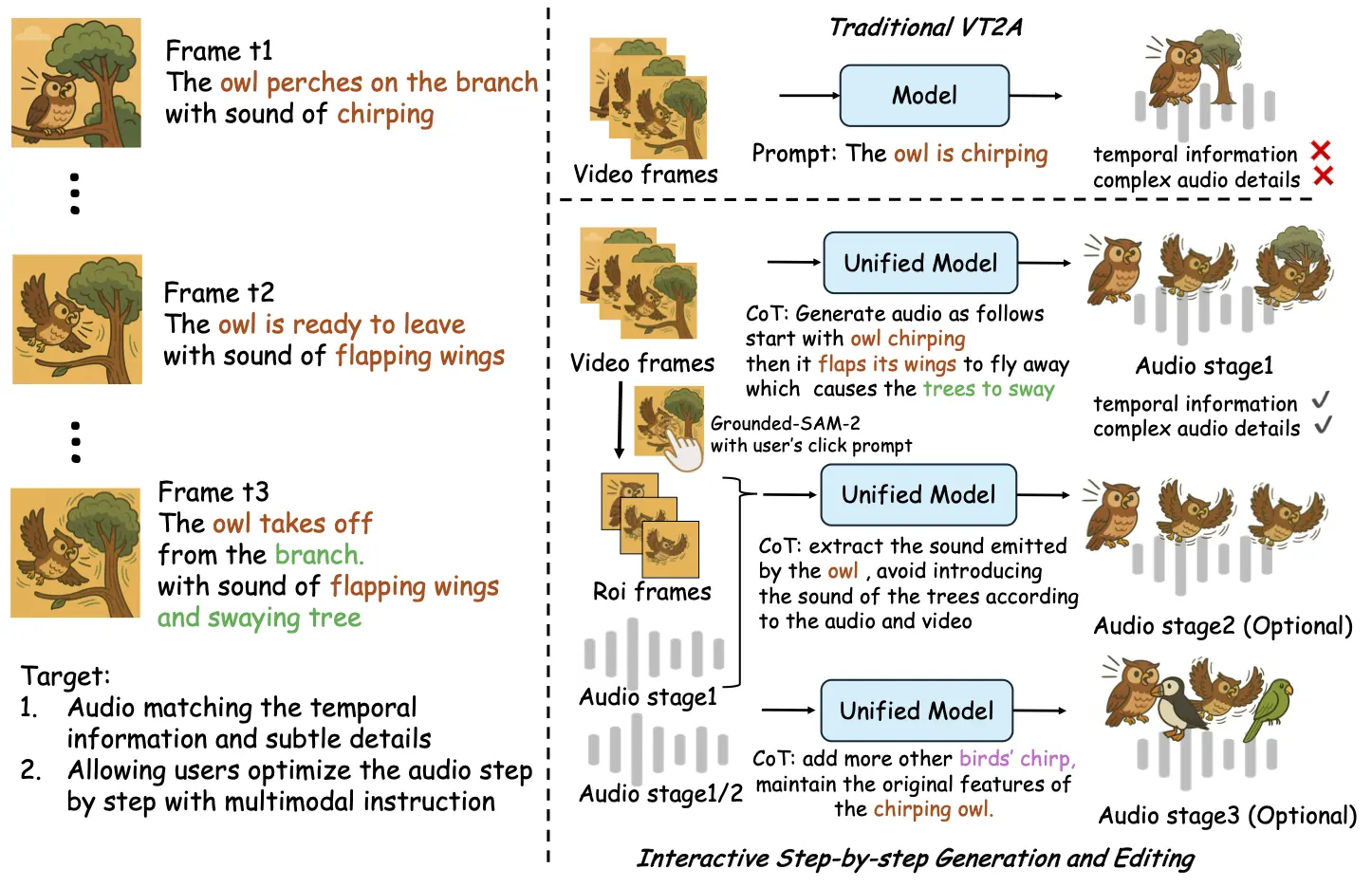
与传统的音频生成技术相比,ThinkSound能够根据三阶段推理从整体画面到具体物体,再到用户指令的响应逐步生成音效。其背后,阿里通义实验室还构建了一个名为AudioCoT的多模态音频数据集,融合了来自多个知名音频平台的2531.8小时高质量样本,涵盖动物叫声、机械运作等多个现实场景,为模型的训练提供了丰富素材。
目前,ThinkSound已正式开源,并将面向全球开发者和创作者开放,进一步推动智能音效技术的发展。通过这一开源平台,用户可以体验到更精细化、个性化的音频生成,未来可能会在虚拟现实、增强现实等领域发挥重要作用。
随着ThinkSound的发布,AI在创意产业的应用范围将得到进一步扩展,音效创作将不再仅仅依赖人工,未来的声音设计可能会由AI与创作者共同完成,开辟出音效生成的新天地。
©版权声明:如无特殊说明,本站所有内容均为AIHub.cn原创发布和所有。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。否则,我站将依法保留追究相关法律责任的权利。
