

Xiaomi MiMo是什么?
MiMo 是小米推出的首个开源推理大语言模型,参数规模为 7B,聚焦于数学推理与代码生成任务。该模型通过高推理密度的预训练数据(总计 25 万亿 tokens)与强化学习后训练(包括奖励机制优化、样本再采样策略等),实现了在 AIME、LiveCodeBench 等多个权威基准上的领先表现。在同等训练资源下,MiMo 在推理能力上超越了部分 30B 级别模型,如 Qwen-32B 和 DeepSeek-R1,展示了中型模型在结构优化与训练策略驱动下的强大潜力,也标志着小米正式进军开源大模型领域。

Xiaomi MiMo 的主要特点
- 专为推理任务设计
MiMo 聚焦于数学推理与代码生成两大“硬逻辑”场景,具备优异的逻辑思维能力,适用于高阶复杂任务。 - 中等规模,高性能
虽为 7B 参数模型,但在多个权威基准(如 AIME、LiveCodeBench、MATH500)中表现优于部分 30B 模型,如 Qwen-32B 和 DeepSeek-R1,性价比高。 - 创新的数据与训练策略
- 使用三阶段 curriculum-style 训练流程,逐步提高训练难度
- 构建并合成高达 200B tokens 的推理语料,总训练量达 25T tokens
- 引入 Multiple Token Prediction(MTP),提高模型生成效率和准确率
- 强化学习优化(RLHF)先进
- 构建 13 万道可验证数学与代码题
- 提出 Test Difficulty Driven Reward,解决稀疏奖励问题
- 引入 Easy Data Re-Sampling 策略,提升 RL 收敛速度与稳定性
- 训练系统 Seamless Rollout Engine 提速训练 2.29×、验证 1.96×
- 完全开源,透明开放
提供基础模型(Base)、监督微调(SFT)与强化学习(RL)版本,配套完整技术报告,支持在 Hugging Face 下载和本地部署。
Xiaomi MiMo 模型版本对比
| 模型名称 | 描述 | Hugging Face 地址 |
|---|---|---|
| MiMo-7B-Base | 预训练基础模型,具备原生推理能力 | 🔗 MiMo-7B-Base |
| MiMo-7B-SFT | 基于 Base 模型的监督微调版本 | 🔗 MiMo-7B-SFT |
| MiMo-7B-RL-Zero | 从 Base 模型直接 RL 微调 | 🔗 MiMo-7B-RL-Zero |
| MiMo-7B-RL | 在 SFT 基础上进行 RL 微调,性能最强 | 🔗 MiMo-7B-RL |
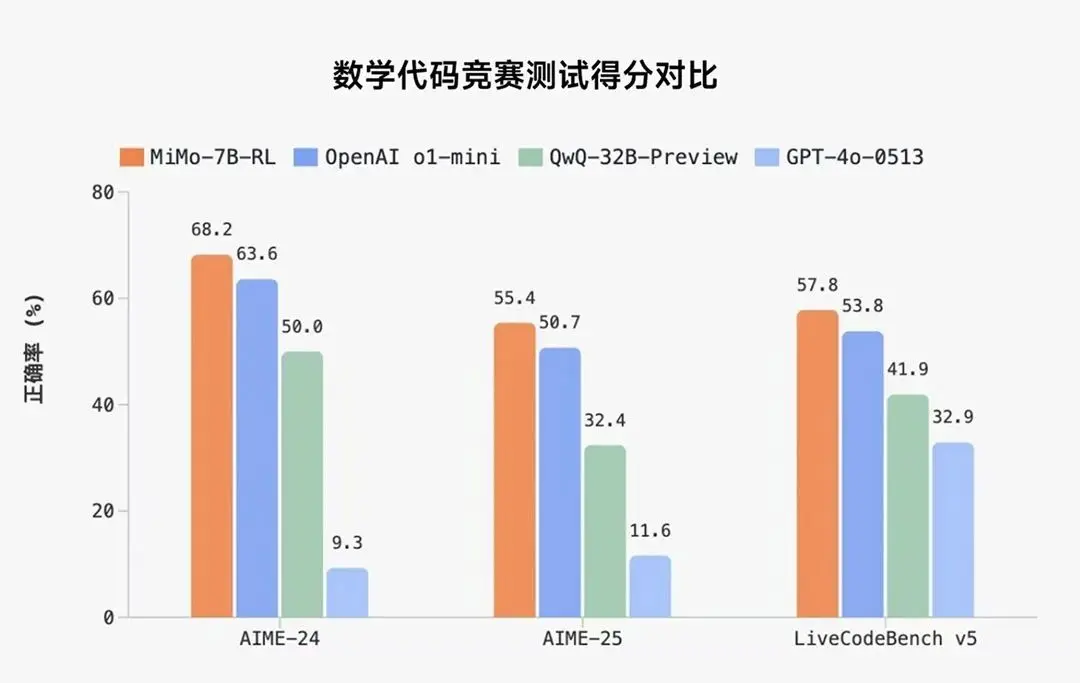
Xiaomi MiMo 的性能评测
在数学推理(AIME 24-25)和代码竞赛(LiveCodeBench v5)上超越在 STEM 领域(科学、技术、工程和数学)表现出色的 OpenAI o1-mini 和 Qwen-32B-Preview。
在相同 RL 训练数据情况下,MiMo-7B 的数学&代码领域的强化学习潜力超越 DeepSeek-R1-Distill-7B 和 Qwen2.5-32B。
Xiaomi MiMo 的项目地址
目前,MiMo-7B 已在 Hugging Face 平台开源 4 个模型版本,技术报告也同步上线 GitHub,向开发者与研究者全面开放。
- GitHub仓库:https://github.com/XiaomiMiMo/MiMo/tree/main
- HuggingFace模型地址:https://huggingface.co/XiaomiMiMo
- GitHub 技术报告:https://github.com/XiaomiMiMo/MiMo/blob/main/MiMo-7B-Technical-Report.pdf
©版权声明:如无特殊说明,本站所有内容均为AIHub.cn原创发布和所有。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。否则,我站将依法保留追究相关法律责任的权利。
