

MiniMax-M1是什么?
MiniMax-M1 是MiniMax(稀宇科技)推出的全球首个开源大规模混合架构推理模型,具备卓越的长上下文处理能力和高效的推理性能。其支持高达100万上下文输入和8万Token输出,采用闪电注意力机制,显著提升算力效率。同时,该模型在软件工程、长上下文理解等复杂场景中表现优异,性价比极高,且提供免费不限量使用和低价格API服务。
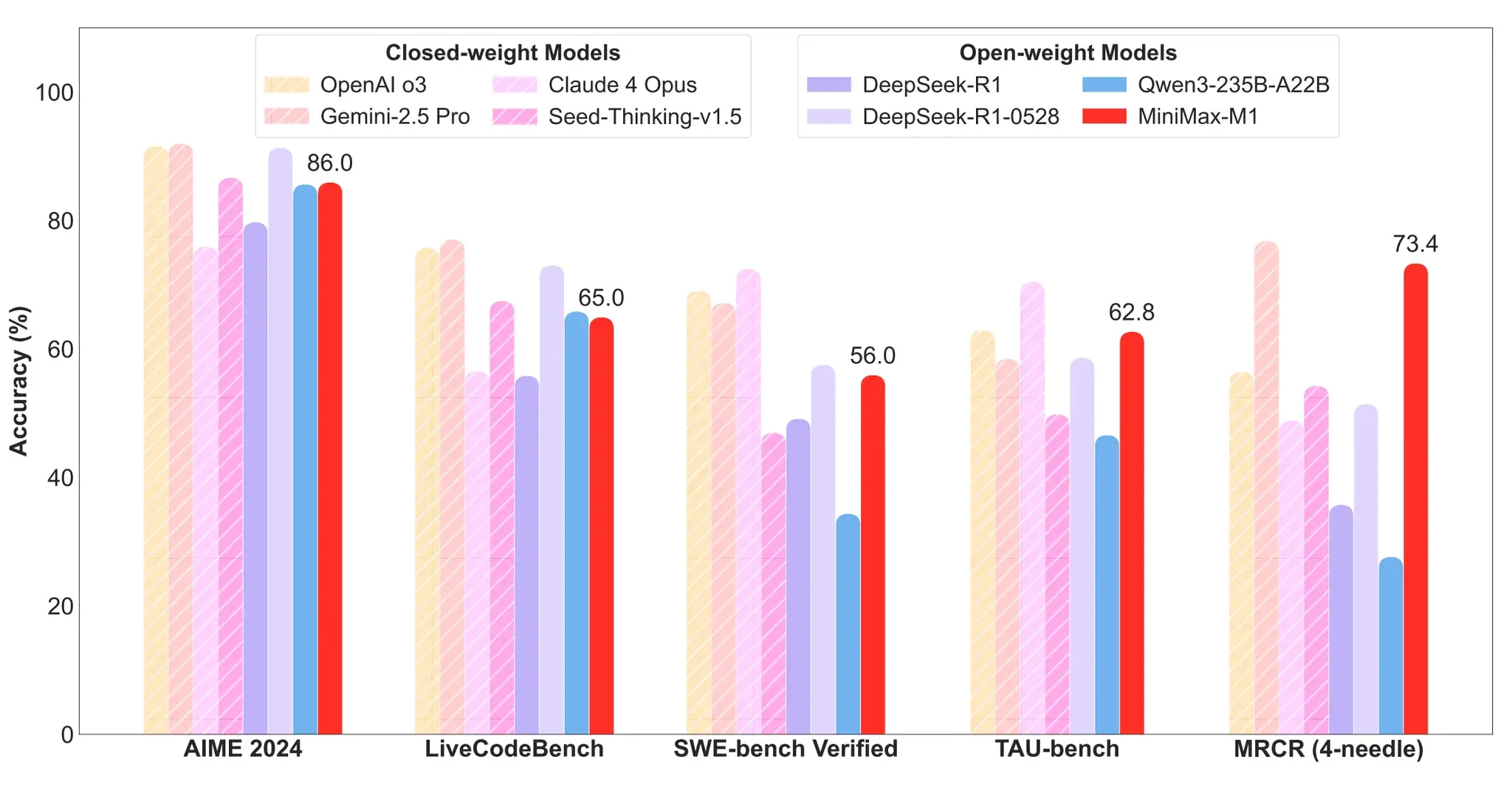
MiniMax-M1的技术优势
- 大规模上下文输入与推理输出
- 支持高达100万上下文的输入,与 Google Gemini 2.5 Pro 相当,是 DeepSeek R1 的8倍。
- 提供业内最长的8万Token的推理输出。
- 这主要得益于其独创的闪电注意力机制为主的混合架构,在处理长上下文输入和深度推理时表现出显著的高效性。例如,在8万Token深度推理时,仅需使用 DeepSeek R1 约30%的算力。
- 高效的强化学习算法
- 提出了更快的强化学习算法 CISPO,通过裁剪重要性采样权重(而非传统 token 更新)提升强化学习效率。
- 在 AIME 实验中,该算法的收敛性能比字节近期提出的 DAPO 等强化学习算法快一倍,显著优于 DeepSeek 早期使用的 GRPO。
- 整个强化学习阶段仅用512块 H800 三周时间,租赁成本仅53.74万美金,比预期少了一个数量级。
MiniMax-M1的性能表现
- 软件工程场景:MiniMax-M1-40k 和 MiniMax-M1-80k 在 SWE-bench 验证基准上分别取得55.6%和56.0%的成绩,略逊于 DeepSeek-R1-0528 的57.6%,但显著超越其他开源权重模型。
- 长上下文理解任务:依托百万级上下文窗口,M1 系列在长上下文理解任务中表现卓越,全面超越所有开源权重模型,甚至超越 OpenAI o3 和 Claude 4 Opus,全球排名第二,仅以微弱差距落后于 Gemini 2.5 Pro。
- 代理工具使用场景
- MiniMax-M1-40k 在 TAU-bench 中领跑所有开源权重模型,并战胜 Gemini-2.5 Pro。
- MiniMax-M1-80k 在大多数基准测试中始终优于 MiniMax-M1-40k,验证了扩展测试时计算资源的有效性。
如何使用MiniMax-M1?
1、普通用户
MiniMax-M1已经在MiniMax Web 和 APP 上都保持不限量免费使用。
2、企业和开发者
MiniMax开发者平台提供业内最低价格的 API 服务:
- 0-32k 输入长度:输入0.8元/百万 token,输出8元/百万 token。
- 32k-128k 输入长度:输入1.2元/百万 token,输出16元/百万 token。
- 128k-1M 输入长度:输入2.4元/百万 token,输出24元/百万 token。
前两种模式性价比高于 DeepSeek-R1,后一种模式 DeepSeek 模型不支持。
3、开源与部署
- 在线体验:https://chat.minimax.io/
- Hugging Face:https://huggingface.co/MiniMaxAI
- GitHub:https://github.com/MiniMax-AI/MiniMax-M1
- 技术报告:https://arxiv.org/abs/2506.13585
©版权声明:如无特殊说明,本站所有内容均为AIHub.cn原创发布和所有。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。否则,我站将依法保留追究相关法律责任的权利。
