

Open-Sora是什么?
Open-Sora 1.0是由Colossal-AI团队开源的类Sora架构视频生成模型,采用Diffusion Transformer(DiT) 架构,能够根据文本提示生成高质量视频内容。该模型通过三个阶段的训练流程实现,包括大规模图像预训练、视频预训练和微调。Open-Sora 1.0的开源降低了视频生成的技术门槛,为AI在视频创作领域的应用开辟了新路径。
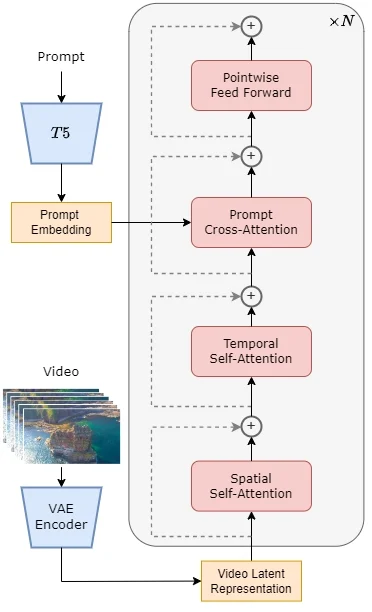
Open-Sora的模型架构
Open-Sora 1.0的模型架构基于当前流行的Diffusion Transformer (DiT) 架构,并针对视频生成任务进行了特别的扩展。以下是该模型架构的关键组成部分:
- 预训练的VAE (Variational Autoencoder):用于对视频数据进行压缩,将数据编码到一个潜在空间中,以便与文本嵌入一起用于后续的生成过程。
- 文本编码器:将输入的文本提示转换为嵌入向量,这些向量在生成过程中与视频特征结合。
- STDiT (Spatial Temporal Diffusion Transformer):这是模型的核心,它结合了空间注意力和时间注意力机制,用于建模视频帧之间的时序关系。STDiT通过串行地在二维空间注意力模块上叠加一维时间注意力模块来实现这一点。
- 交叉注意力模块:在时间注意力模块之后,该模块用于对齐文本的语义信息,与全注意力机制相比,这种结构显著降低了训练和推理的计算开销。
- 训练和推理流程:在训练阶段,首先使用VAE的编码器压缩视频数据,然后在潜在空间中结合文本嵌入训练STDiT扩散模型。在推理阶段,从VAE的潜在空间中采样高斯噪声,并与提示词嵌入一起输入到STDiT中,得到去噪后的特征,最后通过VAE的解码器生成视频。
Open-Sora 1.0的模型架构设计允许它有效地生成与文本描述相匹配的视频内容,同时保持较低的计算成本和高效的训练过程。这种结合了空间和时间信息的混合注意力机制是实现高质量视频生成的关键。
Open-Sora的功能特性
Open-Sora 的主要功能特性包括:
- 完整的Sora复制架构解决方案:提供从数据处理到训练和推理的全过程解决方案。
- 动态分辨率支持:允许直接训练任何分辨率的视频,无需进行缩放处理。
- 多种模型结构:实现了包括adaLN-zero、交叉注意力和上下文条件(token concat)在内的多种常见的多模态模型结构。
- 多种视频压缩方法:用户可以选择使用原始视频、VQVAE(视频原生模型)或SD-VAE(图像原生模型)进行训练。
- 并行训练优化:包括与Colossal-AI兼容的AI大模型系统优化能力,以及与Ulysses和FastSeq的混合序列并行性。
- 性能优化:针对Sora类训练任务的特点(小模型但序列长度异常长),Open-Sora引入了两种不同的序列并行方法,可以与ZeRO一起实现混合并行。
- 成本降低:相比基线解决方案,Open-Sora在600K序列长度下提供了超过40%的性能提升和成本降低。
- 序列长度扩展:Open-Sora能够训练更长的序列,达到819K+,同时保证更快的训练速度。
这些特性使得Open-Sora成为一个高性能、低成本的视频生成模型开发解决方案,有助于推动AI视频生成技术的发展和应用。
如何使用Open-Sora?
- Open-Sora项目主页:https://hpcaitech.github.io/Open-Sora/
- Open-Sora开源地址:https://github.com/hpcaitech/Open-Sora
©版权声明:如无特殊说明,本站所有内容均为AIHub.cn原创发布和所有。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。否则,我站将依法保留追究相关法律责任的权利。
