

ThinkSound 是什么?
ThinkSound 是阿里通义开源的旗下首个音频生成模型,其核心创新在于首次将 CoT(思维链)技术应用于音频生成领域,通过多模态大语言模型(MLLM)与音频生成模型的协同,实现 “像专业音效师一样思考” 的能力,打破传统 “看图配音” 的局限,真正基于画面事件逻辑生成高保真、强同步的空间音频。
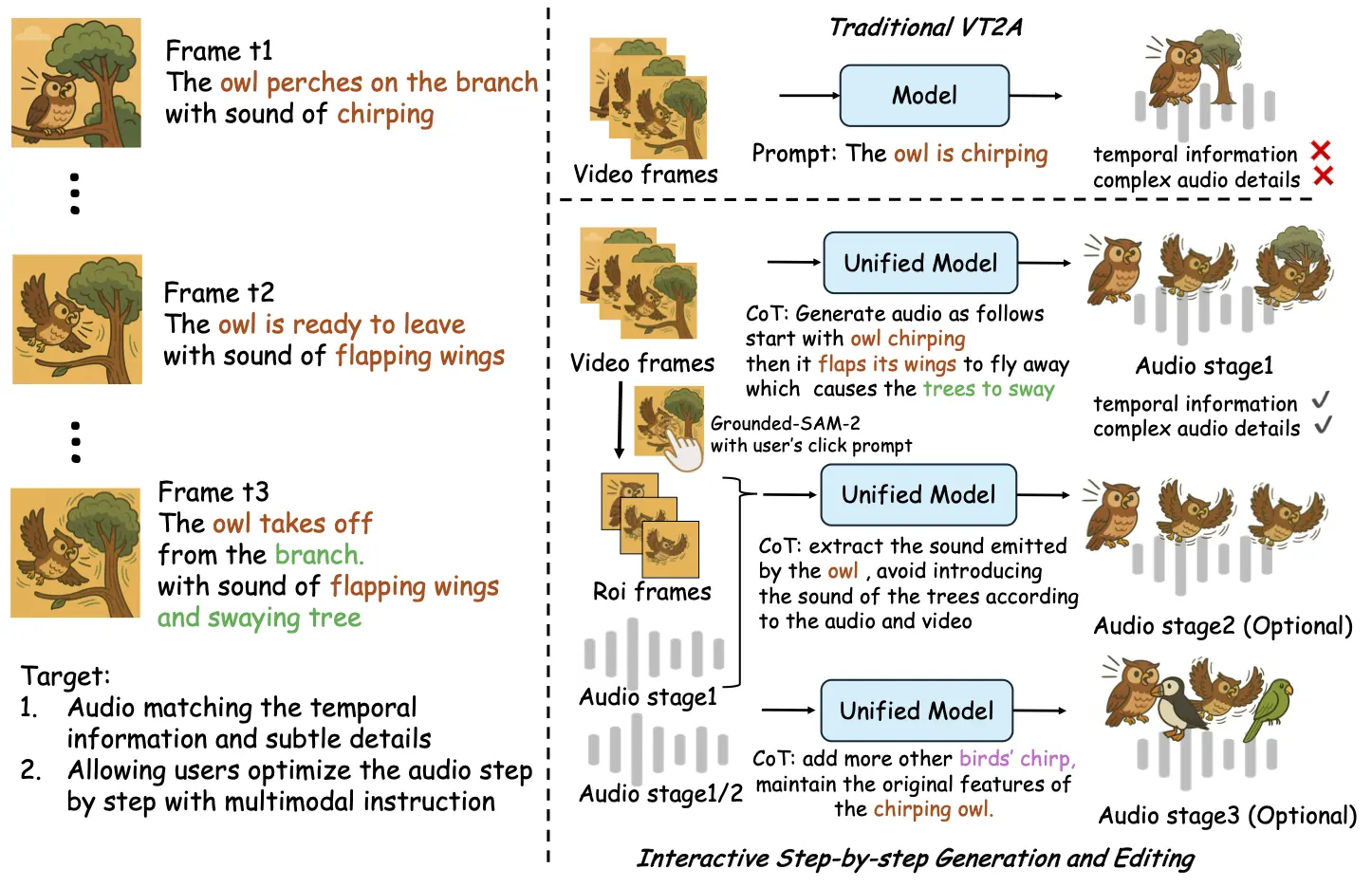
ThinkSound 的主要特性
- Any2Audio:ThinkSound支持任意模态(视频、文本、音频或其组合)生成音频。
- 视频转音频 SOTA:在多个 V2A 基准上取得最新最优结果。
- CoT 驱动推理:基于链式思维推理,实现可组合、可控的音频生成。
- 交互式面向对象编辑:通过点击视觉对象或文本指令,细化或编辑特定声音事件。
- 统一框架:单一基础模型,支持生成、编辑与交互式工作流。
- 全面开源:模型权重、训练代码及 Demo 已公开,便于开发者二次开发与部署。
ThinkSound 的应用场景
- 影视与视频内容创作:为动画、短视频、影视片段自动生成贴合画面的环境音效、物体动作音效,降低专业配音成本。
- 游戏音效设计:根据游戏场景动态生成实时音效(如角色移动、道具交互、场景变换音效),提升沉浸感。
- 多媒体内容编辑:支持用户通过指令交互式调整音频,例如为已有视频添加特定环境音、增强物体音效细节,适用于自媒体、广告制作等场景。
- 虚拟现实(VR/AR):生成与虚拟场景同步的空间音频,增强虚拟环境的真实感,应用于 VR 游戏、虚拟培训等领域。
- 无障碍媒体服务:为视觉障碍用户生成描述性音效,辅助理解画面内容,提升多媒体内容的可访问性。
ThinkSound 的开源地址
- 在线体验Demo:https://www.modelscope.cn/studios/iic/ThinkSound
- GitHub仓库:https://github.com/FunAudioLLM/ThinkSound
- Hugging Face模型:https://huggingface.co/spaces/FunAudioLLM/ThinkSound
©版权声明:如无特殊说明,本站所有内容均为AIHub.cn原创发布和所有。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。否则,我站将依法保留追究相关法律责任的权利。
