


AnimateDiff是什么?
AnimateDiff 是一个能够将个性化的文本转换为图像的扩展模型,它可以在无需特定调整的情况下实现动画效果。通过这个项目,用户可以将他们的想象力以高质量图像的形式展现出来,同时以合理的成本实现这一目标。随着文本到图像模型(例如,Stable Diffusion)和相应的个性化技术(例如,LoRA 和 DreamBooth)的进步,现在每个人都可以将他们的想象力转化为高质量的图像。随后,为了将生成的静态图像与运动动态相结合,对图像动画技术的需求也随之增加。
AnimateDiff可以做什么?
AnimateDiff 提供了一个有效的框架,可以为大多数现有的个性化文本到图像模型提供动画效果,而无需为每个模型进行特定的调整。它的核心思想是向基础的文本到图像模型中添加一个新初始化的运动建模模块,并在视频剪辑上对其进行训练,以提取合理的运动先验。一旦训练完成,只需注入这个运动建模模块,所有从同一基础模型派生的个性化版本都可以立即成为产生多样化和个性化动画图像的文本驱动模型。
AnimateDiff支持镜头平移:远近、左右、上下、旋转等操作。
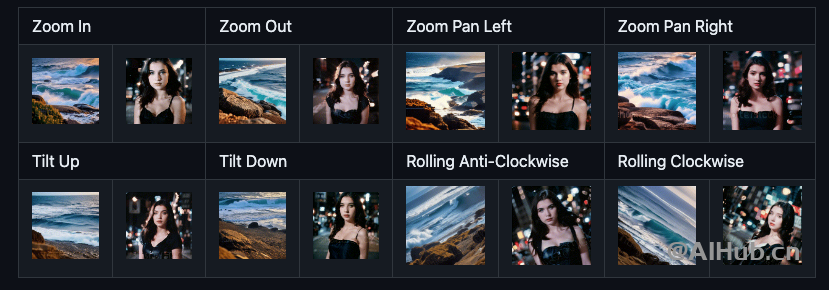
AnimateDiff使用场景
- 动画创建:通过文本输入,用户可以创建个性化的动画图像,将静态图像转变为动态图像,为创意表达提供了一种新的方式。
- 视频制作:为视频制作人员提供了一种新的工具,可以将文本描述转换为动画图像,从而丰富视频内容。
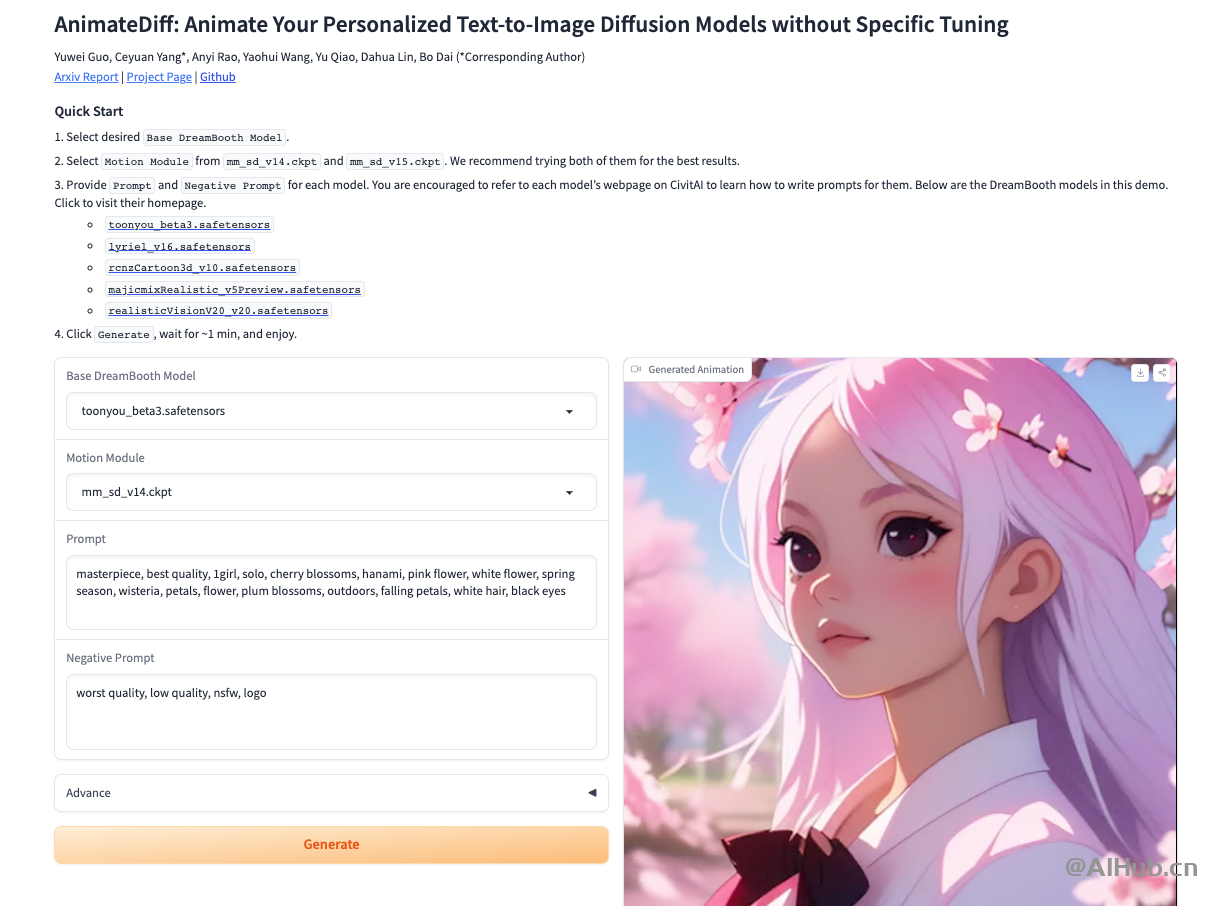
如何使用AnimateDiff?
在线体验:https://huggingface.co/spaces/guoyww/AnimateDiff
项目主页:https://animatediff.github.io/
论文地址:https://arxiv.org/abs/2307.04725
GitHub地址:https://github.com/guoyww/AnimateDiff

©版权声明:如无特殊说明,本站所有内容均为AIHub.cn原创发布和所有。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。否则,我站将依法保留追究相关法律责任的权利。