

AniPortrait是什么?
AniPortrait是一款由腾讯研究人员开发的音频驱动的肖像动画合成框架,能够根据音频和静态人脸图片生成逼真的动态视频。它通过提取音频中的3D面部表情和唇动信息,并结合扩散模型,创造出时间上连贯且高质量的肖像视频。AniPortrait适用于虚拟现实、游戏、数字媒体制作等领域,提供了面部动画编辑和面部再现的灵活性。

AniPortrait主要特性
AniPortrait的主要特性包括:
- 音频驱动的动画生成:能够根据输入的音频信号生成与之相匹配的面部表情和唇动动画。
- 高逼真度输出:生成的动画具有高度的真实感和自然度,使得观众难以区分真实与合成。
- 时间一致性:确保动画在时间轴上的连贯性,提供流畅且无跳跃的动态表现。
- 灵活性和可控性:支持对3D面部表示进行编辑,允许用户进行面部运动编辑和面部再现。
- 高效的训练和推理:使用先进的模型和技术,实现了高效的训练过程和快速的动画生成。
AniPortrait的工作原理
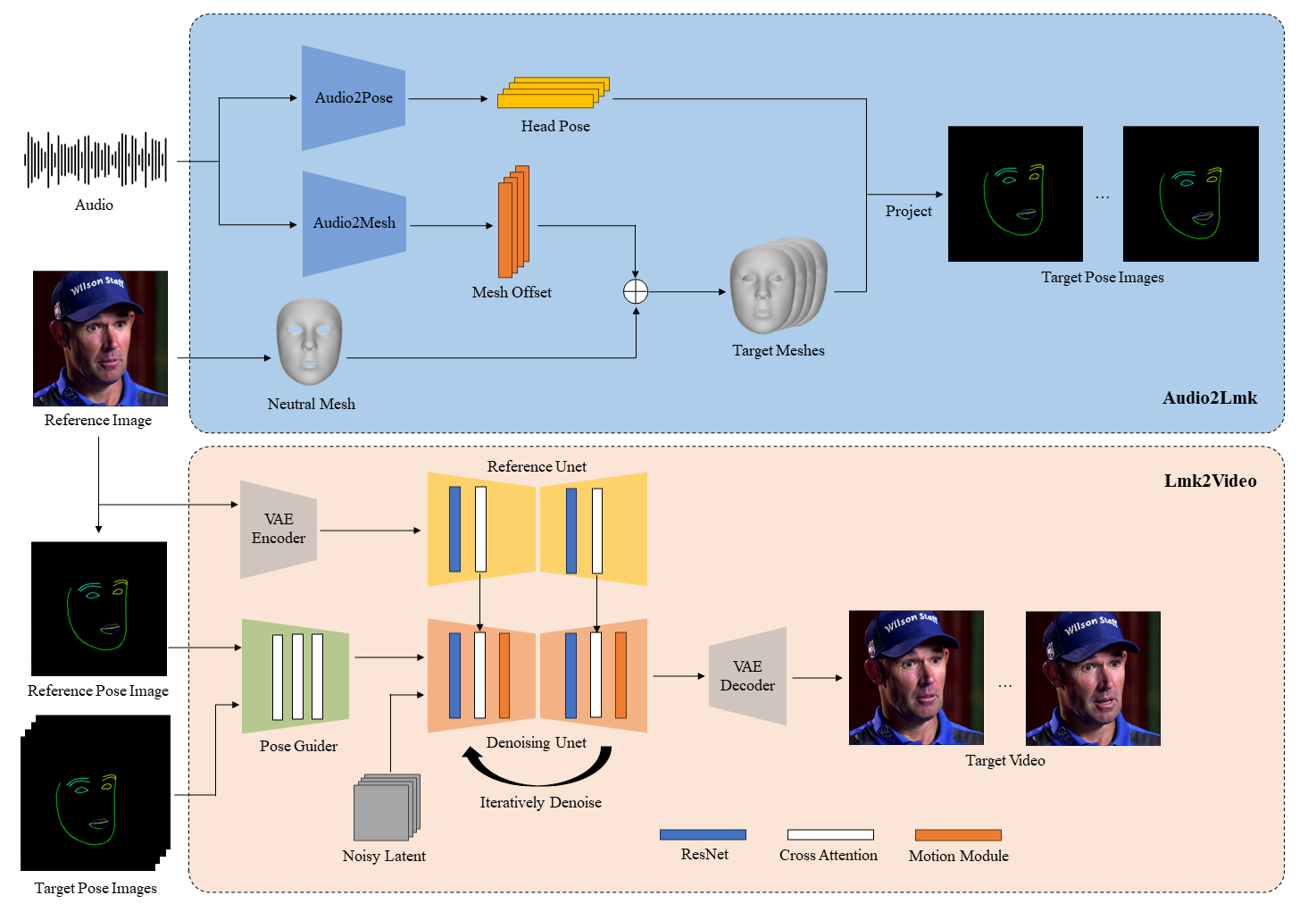
AniPortrait的工作原理分为两个主要阶段:
1、音频处理与3D面部表示:
- 音频特征提取:首先,使用预训练的wav2vec模型从输入的音频中提取关键的语音特征,如发音、语调和节奏。
- 3D面部网格与姿势生成:接着,根据提取的音频特征,通过一个简单的网络架构(通常包含全连接层)生成对应的3D面部网格和头部姿势。这一步骤能够捕捉到微妙的面部表情和唇部动作,以及与音频节奏同步的头部运动。
2、2D标记点到动画的转换:
- 2D面部标记点投影:将3D面部网格和姿势转换为2D面部标记点序列。这些标记点为后续的动画生成提供了关键的视觉信息。
- 扩散模型与动画生成:然后,利用扩散模型(如Stable Diffusion 1.5)结合运动模块,将2D标记点序列转换成一系列动画帧。这一过程中,模型会参考扩散模型的网络架构,通过迭代去噪过程生成高质量的图像。
- PoseGuider模块:为了提高唇部动作的准确性,AniPortrait引入了PoseGuider模块,该模块采用ControlNet的多尺度策略,将不同尺度的标记点特征整合到网络的不同层中。此外,还包括参考图像的标记点作为额外输入,通过交叉注意力机制增强生成动画的精确度。
通过这两个阶段的工作,AniPortrait能够将音频和静态图像转换为逼真的肖像动画,同时保持高度的自然性和时间上的连贯性。这个过程涉及到复杂的深度学习技术和图像处理算法,使得最终输出的动画既符合音频的节奏,又能够精确地模拟人类的面部表情和唇动。
AniPortrait的应用场景
AniPortrait的应用场景包括:
- 虚拟现实(VR):为VR角色提供逼真的面部动画,增强用户的沉浸感。
- 视频游戏:在游戏中生成与玩家语音同步的NPC(非玩家角色)动画,提升游戏体验。
- 数字媒体制作:在电影、电视广告和音乐视频中创建高质量的动画肖像,节省传统动画制作成本。
- 社交媒体内容创作:让内容创作者能够快速生成个性化的动画角色,用于视频博客、直播等。
- 教育和培训:制作教育动画,用于语言学习、表情识别等领域。
- 个性化娱乐:用户可以上传自己的照片和音频,生成个性化的动画肖像,用于娱乐或社交媒体分享。

©版权声明:如无特殊说明,本站所有内容均为AIHub.cn原创发布和所有。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。否则,我站将依法保留追究相关法律责任的权利。