
Khala是什么
Khala 是由中央音乐学院主导、清华大学参与研发的开源高保真歌曲生成系统,支持基于文本描述与歌词条件生成完整歌曲。它的核心差异在于采用统一的声学词元建模路线:不依赖语义 token、扩散模型或多级音频生成模块,而是在同一套离散音频表示空间中,完成从粗粒度音乐结构到细粒度声学细节的生成。模型基于 64 层 RVQ 声学词元层级,将音频表示为由粗到细的离散词元,并通过 backbone 与 super-resolution 的两阶段链路逐层补全、再由 decoder 还原为波形。论文还发现,文本与人声的对齐能力可以在纯声学词元语言建模中自然涌现,无需单独的语义 token 阶段。除模型本身外,项目提供前端界面、FastAPI 后端调度层与单卡推理 worker,构成一套可部署的完整实现。
Khala官网链接:https://github.com/Khala-Music-AI/Khala
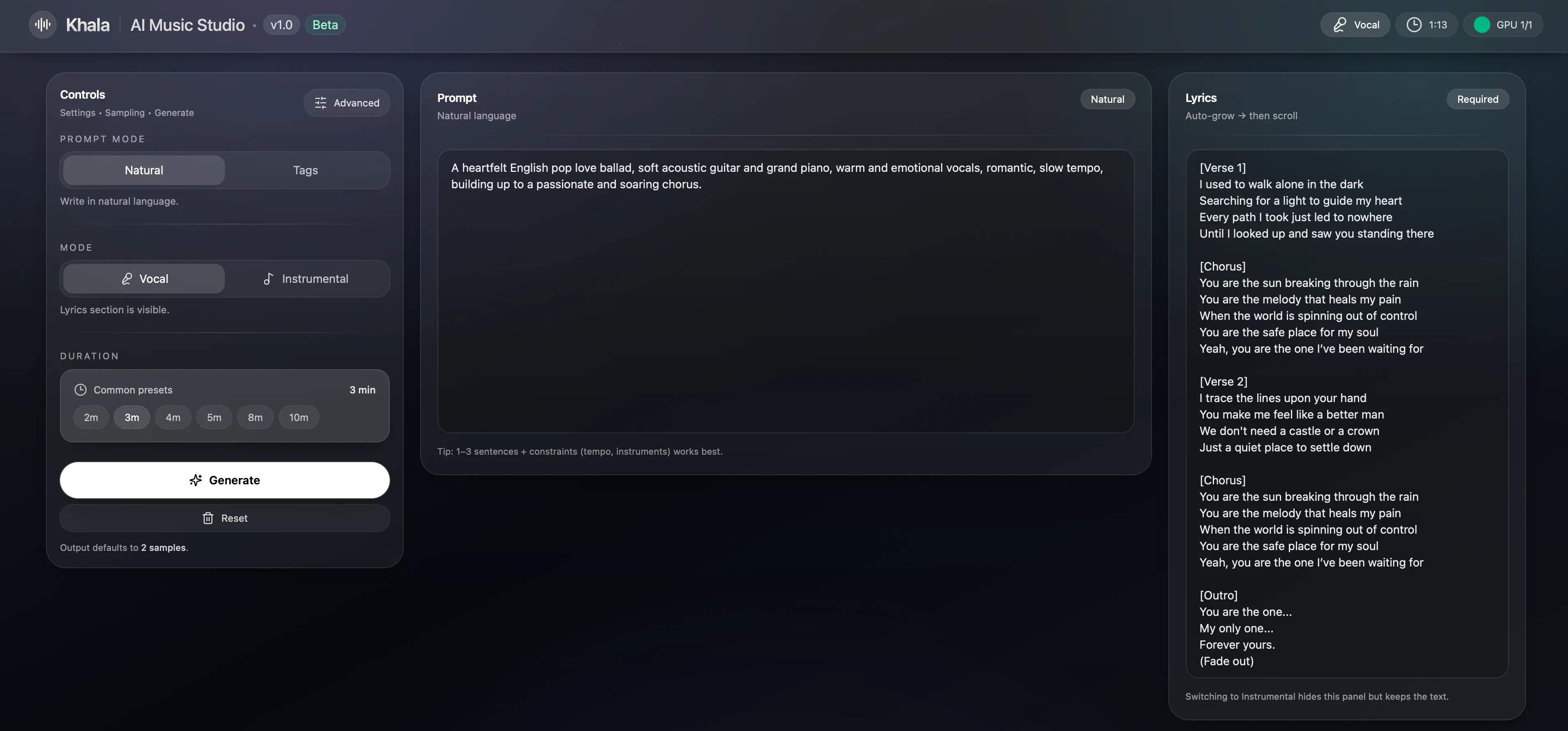
Khala的主要特性
- 完整歌曲生成: 面向歌曲级别的音乐生成,目标是产出完整歌曲,而非短音频片段或伴奏循环。
- 文本与歌词双重控制: 支持通过自然语言 prompt 控制风格与情绪,并以 lyrics 条件控制演唱与内容;前端提供 Prompt 模式与 Tag 模式两种输入方式。
- 统一声学词元表示: 基于 64 层 RVQ acoustic token hierarchy,将音频统一表示为由粗到细的离散声学词元,避免语义 token 与声学 token 分离带来的链路复杂度。
- 两阶段生成链路: 先由 backbone 为整轨生成粗粒度 acoustic tokens,再由 super-resolution 模型在同一词元空间内逐层补全更精细的 tokens,并在时间维度并行运行,形成固定 62 步的推理流程。
- 歌词—人声时间对齐: 通过混合注意力训练(对齐目标用因果注意力、逐层细化用全注意力)联合提升歌词对齐与细节重建,使字、拍与人声起伏的关系更稳定,缓解吞字、错位、倒字等常见问题。
- 统一路线而非扩散/多级方案: 区别于扩散模型或多级音频生成模块的主流路线,整体在离散声学词元空间内建模,技术路径更为统一;用训练好的 backbone 初始化 super-resolution 还能显著改善收敛与最终质量。
- 完整系统实现: 提供前端、API 调度层与推理 worker 的完整链路,而不只是离散的推理脚本,便于自托管部署与二次开发。
Khala的应用场景
- 音乐生成研究: 为声学词元语言模型、高保真音频生成等方向提供可复现的开源基线与论文支撑。
- 歌曲创作原型: 研究者或独立创作者用文本与歌词快速生成完整歌曲样例,用于风格探索与创作原型验证。
- 开发者集成与自建服务: 凭借前端加后端的完整实现,开发者可在自有 GPU 服务器上部署,搭建内部歌曲生成服务。
- 文本/标签到歌曲: 适用于将 prompt 描述或风格标签转化为成品歌曲的生成任务。
Khala的产品定价
Khala 为开源项目,代码与模型权重免费获取。模型权重计划采用 CC BY-NC 4.0 协议发布,即允许署名前提下的非商业性使用,商业用途需另行确认授权。实际使用主要成本来自自托管所需的 GPU 算力(官方推荐 24GB 或以上显存的 NVIDIA GPU,如 RTX 4090 或更高规格)。具体协议条款与权重授权以官方仓库及 Hugging Face 页面为准。
如何使用Khala
- 在线试听样例: 通过官方 Demo 页面试听生成效果 https://khala-music-ai.github.io/Khala-demo/
- 准备运行环境: 拉取官方预构建 Docker 镜像并以 GPU 模式启动容器(需 Docker 与 NVIDIA Container Toolkit)。
- 克隆仓库: 进入容器后克隆代码 https://github.com/Khala-Music-AI/Khala
- 下载模型权重: 从 Hugging Face 将 Khala-MusicGeneration-v1.0 下载到仓库根目录的
checkpoints/目录。 - 启动后端与前端: 在 backend 目录运行启动脚本(默认单卡安全模式),再在 frontend 目录安装依赖并启动开发服务。
- 打开页面生成: 访问默认地址(http://127.0.0.1:30869 ,输入prompt 或 lyrics 生成歌曲。
常见问题
Q:Khala 是谁研发的?
A:Khala 由中央音乐学院主导研发、清华大学参与,论文通讯作者为清华大学的 Maosong Sun(孙茂松),项目以 Khala-Music-AI 团队名义在 GitHub 与 Hugging Face 开源。
Q:Khala 是开源的吗?可以商用吗?
A:Khala 代码开源,模型权重计划采用 CC BY-NC 4.0 协议,允许署名前提下的非商业性使用,商业用途需另行确认授权,具体以官方说明为准。
Q:运行 Khala 需要什么硬件?
A:当前版本主要面向具备 GPU 服务器经验的研究人员与开发者,官方推荐 24GB 或以上显存的 NVIDIA GPU(如 RTX 4090 或更高),并需 Docker 与 NVIDIA Container Toolkit 环境。
Q:Khala 和扩散类、语义 token 类音乐生成模型有什么不同?
A:多数方案依赖语义 token、扩散模型或多级音频生成模块,而 Khala 采用统一的声学词元建模路线,在同一套离散声学词元空间内由粗到细完成生成,链路更统一,且文本—人声对齐可在纯声学词元建模中自然涌现。
Q:当前版本生成质量稳定吗?
A:官方在仓库中提示,已发现一个可能显著影响推理质量的问题,疑似与数值精度有关,正在排查修复中。在该提示移除前,建议谨慎看待当前版本的生成质量。
Q:有现成的在线产品或 API 吗?
A:目前以开源自托管为主,官方提供在线 Demo 页面用于试听样例,但未提供面向终端用户的托管产品或公开 API,需自行部署使用。

©版权声明:如无特殊说明,本站所有内容均为AIHub.cn原创发布和所有。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。否则,我站将依法保留追究相关法律责任的权利。