

4 月 17 日消息,昆仑万维今日宣布,天工 3.0 大模型性能提升显著,旗下的天工 SkyMusic 音乐大模型也在今日面向全社会开放公测。
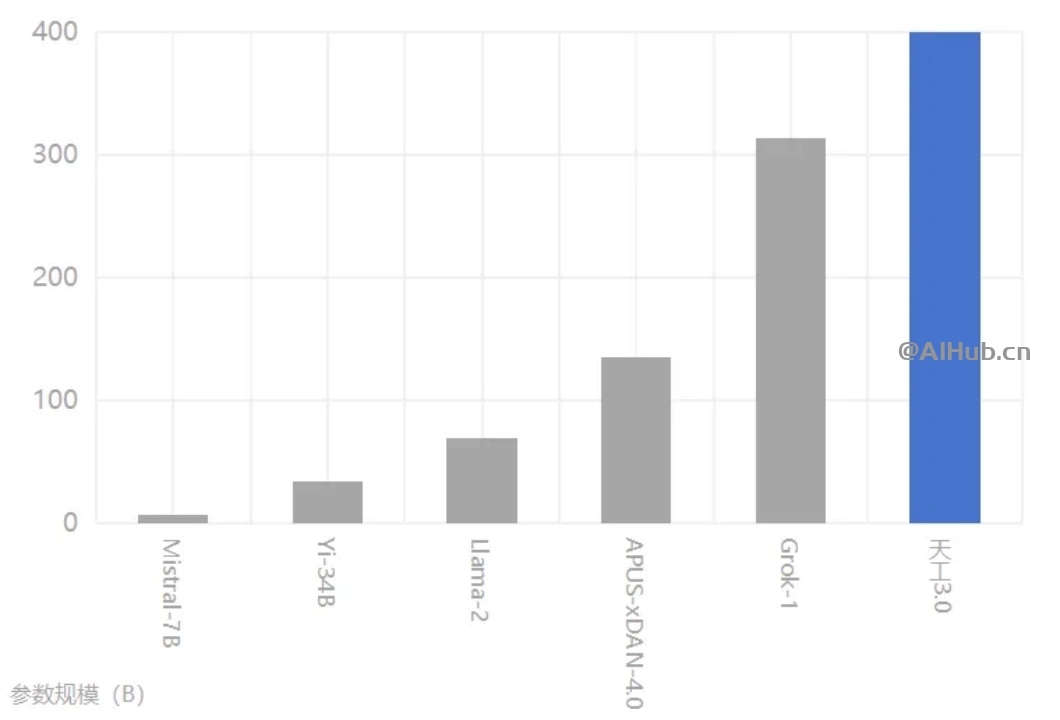
天工 3.0 拥有 4000 亿参数,超越了 3140 亿参数的 Grok-1,是全球最大的开源 MoE 大模型。天工 3.0 在语义理解、逻辑推理、通用性、泛化性、不确定性知识、学习能力等领域性能提升显著,数学 / 推理 / 代码 / 文创能力提升超过 30%。天工 3.0 新增了多轮搜索与综合工具调用、图表绘制、研究模式、增强模式、改图扩图等多项 AI 能力。
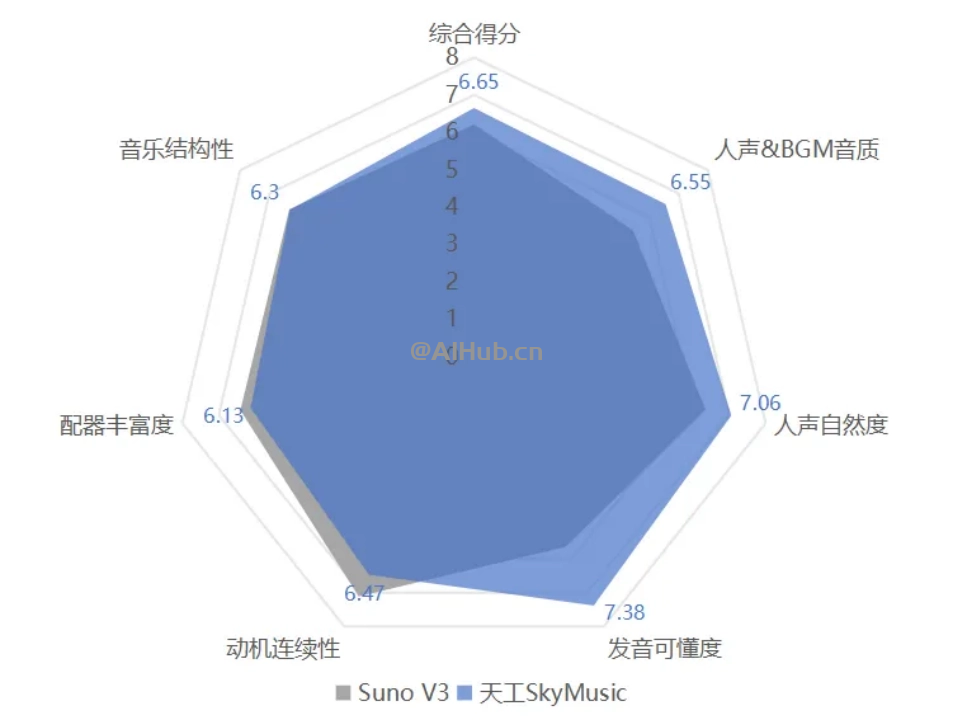
天工 3.0 旗下的天工 SkyMusic 音乐大模型也在今日面向全社会开放公测。昆仑万维表示天工 SkyMusic 在人声 & BGM 音质、人声自然度、发音可懂度等领域“显著”领先对手,综合性能超越 Suno V3,取得音乐大模型 SOTA(State of the art model,即在当前研究中表现最好的模型)。
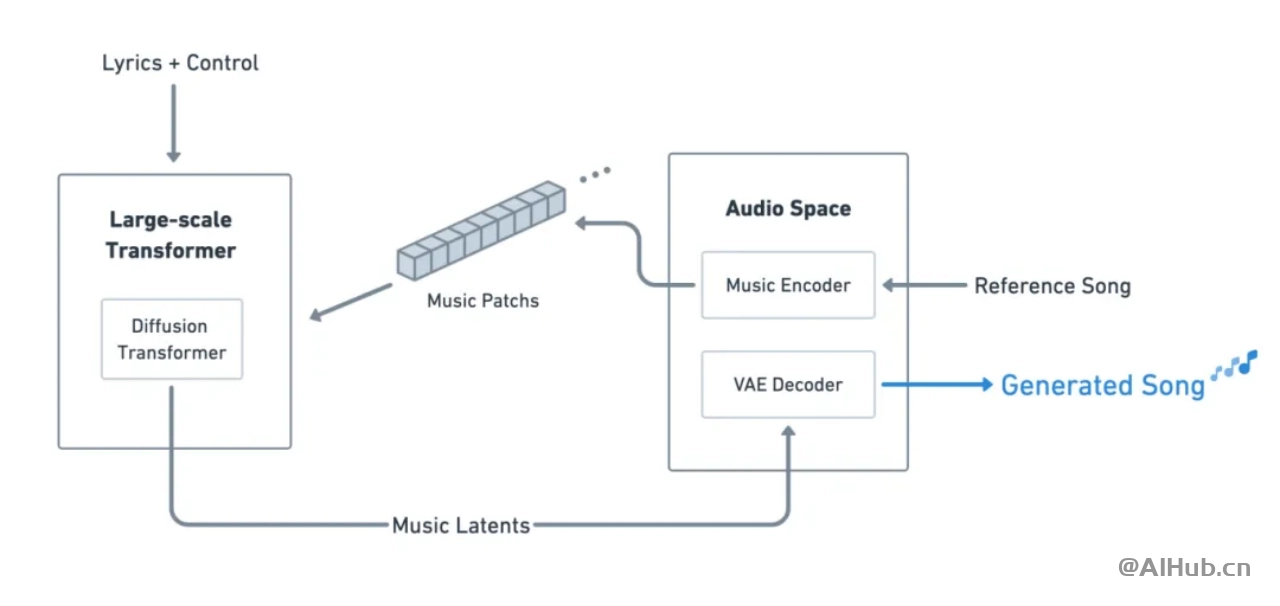
天工 SkyMusic 采用音乐音频领域类 Sora 模型架构,Large-scale Transformer 负责谱曲,来学习 Music Patches 的上下文依赖关系,同时完成音乐可控性,Diffusion Transformer 负责演唱,通过 LDM 让 Music Patches 被还原成高质量音频,使其能够支持生成 80 秒 44100Hz 采样率双声道立体声歌曲。
据介绍,天工 SkyMusic 具备以下特点:
- 高质量 AI 音乐:生成 80 秒 44100Hz 采样率双声道立体声 AI 歌曲
- 人声“以假乱真”:中文水平极为优秀,发音清晰无异响
- 歌词段落控制:生成的歌曲可以明确分辨出不同歌词段落的情绪变化
- 多种音乐风格:支持说唱 / 民谣 / 放克 / 古风 / 电子等
- 音乐智能表达:能够学习如颤音、歌剧、吟唱、男女对唱,自动和声等多种歌唱技巧
- 参考音乐生成:用户上传自有参考音乐,生成风格、唱腔类似的歌曲
- 方言歌曲生成:支持粤语、成都话、北京话等众多方言
昆仑万维是中国互联网平台出海企业,深耕海外市场十余载,业务覆盖包括信息分发、社交、 娱乐、元宇宙、游戏及 AIGC 等多个领域,旗下包括 AGI 与 AIGC 、海外信息分发与元宇宙、投资等三大业务板块,市场遍及中国、东南亚、非洲、中东、北美、南美、欧洲等地。截至目前,全球平均月活跃用户近 4 亿,海外收入占比达 84%。

©版权声明:如无特殊说明,本站所有内容均为AIHub.cn原创发布和所有。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。否则,我站将依法保留追究相关法律责任的权利。