

豆包·视觉理解模型是什么?
豆包·视觉理解模型是豆包推出的多模态大模型,具备强大的图片理解与推理能力,以及精准的指令理解能力。模型在图像文本信息抽取、基于图像的推理任务上有展现出了强大的性能,能够应用于更复杂、更广泛的视觉问答任务。
豆包·视觉理解模型的主要功能
- 更强的内容识别能力:不仅可以识别出图像中的物体类别、形状等基本要素,还能理解物体之间的关系、空间布局以及场景的整体含义。
- 更强的理解和推理能力:不仅能更好地识别内容,还能根据所识别的文字和图像信息进行复杂的逻辑计算。
- 更细腻的视觉描述能力:可以基于图像信息,更细腻地描述图像呈现的内容,还能进行多种文体的创作。
豆包·视觉理解模型的应用场景
豆包·视觉理解模型在教育、旅游、电商等场景有着非常广泛的应用。
例如在教育场景中,为学生优化作文、科普知识;在旅游场景中,帮助游客看外文菜单、讲解照片中建筑的背景知识;在电商营销场景中,帮助商家充分描述商品细节,高效发布种草广告等等。
视觉理解能力将极大拓展大模型的场景边界,为大模型的场景使用打开天花板,在金融、医疗、建筑、地理、体育、物流等诸多行业还有非常广阔的应用前景。
豆包·视觉理解模型的产品价格
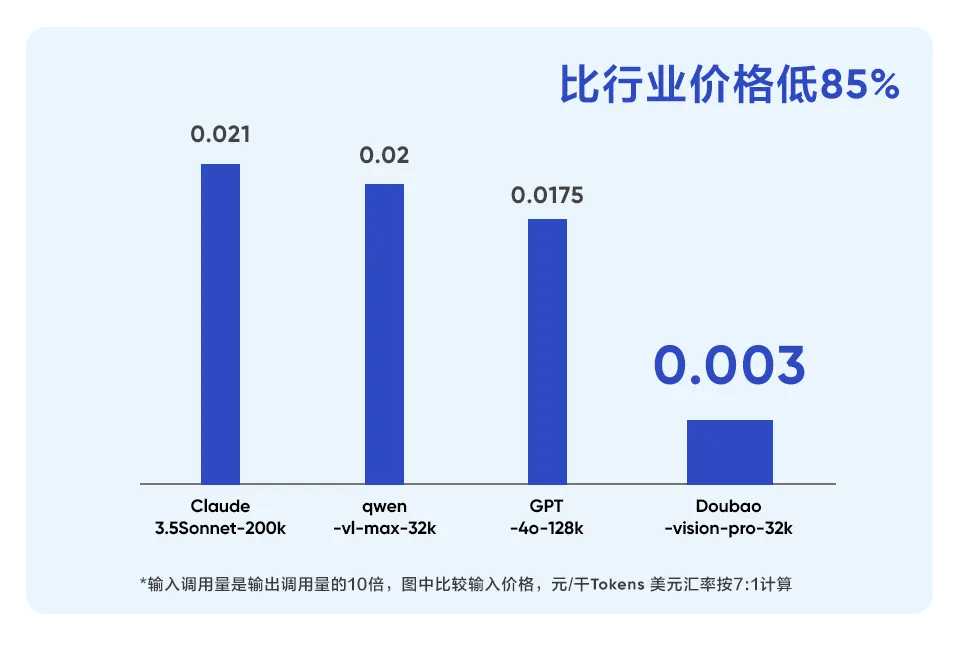
豆包·视觉理解的输入价格为每千tokens 0.003元,比行业平均价格降低85%,相当于一块钱可以处理284张720P的图片,视觉理解模型正式走进厘时代。同时火山引擎还将提供更高的初始流量,RPM达到了15,000次,TPM达到120万,让企业和开发者用好视觉理解模型,找到更多创新场景。
如何使用豆包·视觉理解模型?
2、开发者:前往火山引擎平台体验和接入使用。

©版权声明:如无特殊说明,本站所有内容均为AIHub.cn原创发布和所有。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。否则,我站将依法保留追究相关法律责任的权利。